
Sommaire
Un jour, quelqu’un m’a posé cette question : “Comment créer un assistant qui ne mente jamais, qui ne fabule pas, qui reste fidèle aux documents qu’on lui confie ?”
La réponse tenait en trois lettres : RAG.
Retrieval-Augmented Generation. Un nom savant pour une idée simple : avant de répondre, cherche d’abord dans les archives.
C’est ainsi qu’est né Nico, un gardien des savoirs institutionnels. Pas un oracle qui devine, pas un poète qui improvise — juste un bibliothécaire augmenté, capable de fouiller une base documentaire et de restituer l’information avec précision.
Dans ce projet, je vous raconte comment j’ai construit cet assistant conversationnel en combinant la puissance de FAISS pour la recherche vectorielle, Gemini pour la génération de texte, et FastAPI pour l’exposition de l’API. Une architecture simple mais efficace, pensée pour répondre à un besoin concret : offrir un accès rapide et fiable à l’information institutionnelle.
Contexte et Objectif du Projet
Les institutions — qu’il s’agisse d’écoles, d’administrations ou d’entreprises — accumulent une masse considérable de documents : plaquettes de formation, règlements intérieurs, FAQ, maquettes pédagogiques, contacts administratifs…
Le problème ? Ces informations sont souvent dispersées, difficiles à retrouver, et surtout : inaccessibles 24/7.
L’objectif de ce projet était de créer un assistant virtuel capable de :
- Répondre instantanément aux questions des visiteurs
- Puiser ses réponses dans une base documentaire interne (pas d’invention, pas d’hallucination)
- Rester factuel, professionnel, et toujours cohérent avec les sources officielles
- Être accessible en permanence via une API REST simple
Nico n’est pas un ChatGPT institutionnel. C’est un outil de récupération et de restitution d’informations — un pont entre des documents statiques et une interface conversationnelle.
Pourquoi un RAG plutôt qu’un Simple Chatbot ?
On aurait pu utiliser directement un grand modèle de langage comme ChatGPT ou Gemini pour répondre aux questions. Mais cette approche pose plusieurs problèmes.
Les limites d’un LLM seul :
- Hallucinations : le modèle peut inventer des informations plausibles mais fausses
- Absence de contexte institutionnel : il ne connaît pas les spécificités de votre organisation
- Réponses génériques : il va donner une réponse “probable”, pas une réponse basée sur vos documents officiels
- Pas de traçabilité : impossible de savoir d’où vient l’information
L’approche RAG résout ces problèmes en trois temps :
- Retrieval (Récupération) : Avant de répondre, le système cherche les documents pertinents dans une base vectorielle
- Augmentation : Ces documents sont ajoutés au contexte de la requête
- Generation : Le LLM génère une réponse en s’appuyant uniquement sur ces documents
Résultat : des réponses fidèles aux sources, traçables, et factuelles.
Un LLM seul devine. Un système RAG cherche d’abord, puis restitue.
Le Grimoire des Données
Avant de construire un assistant qui répond, il faut d’abord nourrir sa mémoire.
Constitution du Corpus
Pour ce projet, j’ai collecté et préparé des documents institutionnels :
- Extraction depuis les pages web officielles via web scraping
- Documents PDF (plaquettes, règlements)
- Fichiers texte structurés
- FAQ existantes
La qualité du chatbot dépend entièrement de la qualité de ces documents sources. Garbage in, garbage out.
Segmentation : Découper pour Mieux Régner
Les documents bruts ne peuvent pas être directement exploités. Il faut les découper en morceaux digestes — ce qu’on appelle des “chunks” (segments).
J’ai utilisé le RecursiveCharacterTextSplitter de LangChain avec :
- Taille de chunk : 500 caractères (équilibre entre précision et contexte)
- Chevauchement : 50 caractères (pour éviter de couper des phrases importantes)
Pourquoi ce découpage ? Imaginez que vous cherchiez une information dans une encyclopédie. Vous ne lisez pas tout le livre — vous cherchez le paragraphe pertinent. C’est exactement ce que fait le système.
Vectorisation : Transformer le Sens en Nombres
Une fois les documents segmentés, chaque chunk est transformé en embedding — une représentation vectorielle qui capture son sens sémantique.
J’ai utilisé le modèle d’embeddings de Google (embedding-001) pour cette transformation. Chaque segment devient alors un point dans un espace multidimensionnel, où les segments sémantiquement proches sont géométriquement proches.
Indexation avec FAISS : La Bibliothèque Enchantée
FAISS (Facebook AI Similarity Search) est une bibliothèque optimisée pour la recherche de similarité vectorielle. C’est notre bibliothèque enchantée : on y stocke des milliers de segments, et elle nous retourne instantanément les plus pertinents pour une requête donnée.
Imaginez une bibliothèque infinie où chaque livre est classé non par titre, mais par sens. Quand vous posez une question, le bibliothécaire ne cherche pas mot à mot — il cherche par proximité sémantique.
Architecture du Système
L’architecture de Nico repose sur trois piliers complémentaires.
Le Retriever : FAISS comme Moteur de Recherche Sémantique
Quand un utilisateur pose une question, le système :
- Transforme la question en vecteur (embedding)
- Compare ce vecteur à tous les chunks stockés dans FAISS
- Retourne les 3 documents les plus proches sémantiquement (k=3)
Pourquoi 3 documents ? C’est un compromis. Avec un seul document, les réponses sont trop restreintes. Avec 10 documents, il y a trop de bruit et le modèle se perd. Trois documents offrent assez de contexte sans noyer l’information pertinente.
Le Generator : Gemini comme Conteur
Une fois les documents récupérés, il faut les transformer en une réponse naturelle et fluide. C’est le rôle du modèle de génération.
J’ai utilisé Gemini Flash pour ce projet. Pourquoi Flash ?
- Rapide (faible latence)
- Gratuit pour prototyper
- Suffisant pour de la restitution factuelle
Note importante : Flash n’est pas le modèle le plus puissant. Pour des cas d’usage en production nécessitant plus de finesse, on peut utiliser Gemini Pro, Claude Sonnet, ou GPT-4. L’architecture RAG est agnostique au modèle — vous pouvez changer de LLM sans toucher au reste du système.
Le Pont : FastAPI pour l’Exposition
Pour rendre Nico accessible, j’ai construit une API REST avec FastAPI.
Pourquoi FastAPI ?
- Simplicité : mise en place rapide avec peu de code
- Documentation auto-générée : Swagger UI disponible instantanément
- Typage moderne : validation des données avec Pydantic
- Performances : basé sur Starlette et conçu pour être rapide
L’API expose un endpoint /chat qui accepte une question en JSON et retourne une réponse structurée. Rien de plus, rien de moins.
Le Prompt Engineering : L’Art de Guider le Modèle
Le prompt est la clé pour éviter les hallucinations. J’ai structuré le prompt avec des règles strictes :
- Identité claire : “Tu es Nico, assistant officiel de l’institution”
- Contrainte sur les sources : “Utilise UNIQUEMENT les documents fournis”
- Interdiction de redirection : “Ne redirige JAMAIS vers un site externe”
- Ton professionnel : “Adopte un ton institutionnel”
- Gestion de l’incertitude : “Si tu ne sais pas, dis-le simplement”
Ces règles transforment un LLM généraliste en assistant spécialisé. Sans elles, le modèle inventerait, extrapoleraient, comblerait les vides avec des probabilités. Avec elles, il reste dans son rôle.
Les Défis du Gardien des Savoirs
Construire Nico n’a pas été un long fleuve tranquille. Voici les principaux défis rencontrés et comment je les ai résolus.
Défi 1 : Les Hallucinations du Modèle
Problème : Le LLM a tendance à “remplir les blancs” quand il ne sait pas. Il invente des informations plausibles mais fausses.
Solution :
- Prompt strict avec interdiction explicite d’inventer
- Retour d’un message par défaut si aucun document pertinent n’est trouvé
- Tests réguliers avec des questions pièges pour vérifier la fiabilité
“Si tu ne sais pas, dis ‘je ne sais pas’.” Simple, mais révolutionnaire pour un LLM.
Défi 2 : Le Formatage des Réponses
Problème : Le modèle générait des phrases génériques comme “Selon les documents que j’ai analysés…” ou “D’après mes recherches…”. Ces formulations brisaient l’immersion et rendaient les réponses moins naturelles.
Solution :
- Ajout d’une règle dans le prompt : “Donne l’information directement, sans mentionner comment tu l’as obtenue”
- Post-traitement pour nettoyer les réponses si nécessaire
Défi 3 : La Gestion du Contexte
Problème : Trouver le bon équilibre pour le nombre de documents à récupérer (k). Trop peu = réponses incomplètes. Trop = bruit et confusion.
Solution :
- Réglage empirique à k=3 après plusieurs tests
- Ce nombre peut être ajusté selon le cas d’usage et la longueur moyenne des chunks
Défi 4 : Les Limites de FAISS
Problème : FAISS est excellent pour la recherche, mais ne supporte pas facilement les mises à jour incrémentales. Ajouter un nouveau document nécessite de régénérer l’index complet.
Solution actuelle :
- Régénération périodique de l’index quand de nouveaux documents sont ajoutés
Pistes d’amélioration :
- Pour de très grandes bases nécessitant des mises à jour fréquentes, considérer des alternatives comme Pinecone, Weaviate, ou Chroma qui supportent mieux les mises à jour dynamiques
Déploiement avec Docker
Pour rendre le projet facilement déployable, j’ai créé une image Docker. L’objectif était simple : permettre à quiconque de lancer Nico en quelques commandes, sans se soucier des dépendances.
Avantages de la dockerisation :
- Environnement isolé et reproductible
- Déploiement simplifié sur n’importe quelle machine
- Facilite la collaboration et l’intégration continue
L’image est disponible publiquement sur Docker Hub : roy61/chatbotdit-rag
Lancement en quelques secondes :
| |
Une fois lancé, l’API est accessible via :
- Interface Swagger :
http://127.0.0.1:8000/docs - Endpoint chat :
http://127.0.0.1:8000/chat
Retour d’Expérience et Transmission
Ce projet n’est pas resté dans mon ordinateur. J’ai eu l’immense plaisir de le partager lors d’une formation pratique organisée par JokkoTech Community, co-animée avec Serge Mendy, une personne que je respecte énormément pour son engagement dans la transmission des savoirs en IA.
Ce que les Apprenants ont Découvert
- L’importance cruciale de la préparation des données (garbage in, garbage out)
- La différence fondamentale entre un LLM seul et un système RAG
- Les limites actuelles des modèles (hallucinations, biais, absence de raisonnement)
- La puissance d’une API simple pour démocratiser l’accès à l’information
Questions Mémorables
“Pourquoi FAISS et pas une simple recherche par mots-clés ?”
Parce que la recherche sémantique capture le sens, pas juste les mots. Quelqu’un qui demande “Quelles formations en informatique ?” et quelqu’un qui demande “Quels cursus tech ?” posent la même question avec des mots différents. FAISS le comprend.
“Peut-on utiliser ce système pour des documents confidentiels ?”
Absolument. Tout reste en local si vous le souhaitez. Pas besoin d’envoyer vos données vers un cloud externe.
“Et si le modèle invente quand même ?”
C’est pour ça qu’on teste, qu’on itère sur le prompt, et qu’on garde toujours un œil humain. L’IA n’est pas autonome — elle est assistée.
Cette expérience m’a rappelé que la technique n’a de valeur que si elle est partagée. Un projet qui reste sur GitHub sans documentation ni transmission est un projet à moitié fini.
Impact et Utilité
Cas d’Usage Concrets
- Support client automatisé 24/7 : répondre aux questions fréquentes sans intervention humaine
- Aide à la navigation documentaire : orienter les visiteurs vers les bonnes informations
- Réduction de la charge administrative : libérer du temps pour les tâches à forte valeur ajoutée
- Accès rapide aux règlements et procédures : éviter les allers-retours par email
Limites Actuelles
- Dépendant de la qualité des sources : si les documents sont incomplets ou obsolètes, les réponses le seront aussi
- Pas de raisonnement complexe : Nico restitue, il ne raisonne pas
- Mise à jour manuelle : ajouter de nouveaux documents nécessite de régénérer l’index
Pistes d’Amélioration
- Ajouter un système de feedback utilisateur (pouce en haut/bas pour évaluer les réponses)
- Intégrer des sources multiples (web scraping, API externes, bases de données)
- Mettre en place un pipeline de mise à jour automatique des documents
- Tester d’autres vector stores (Chroma, Pinecone, Weaviate) pour des mises à jour dynamiques
- Expérimenter avec des modèles plus puissants (Gemini Pro, Claude Sonnet) pour améliorer la qualité des réponses
Visuels
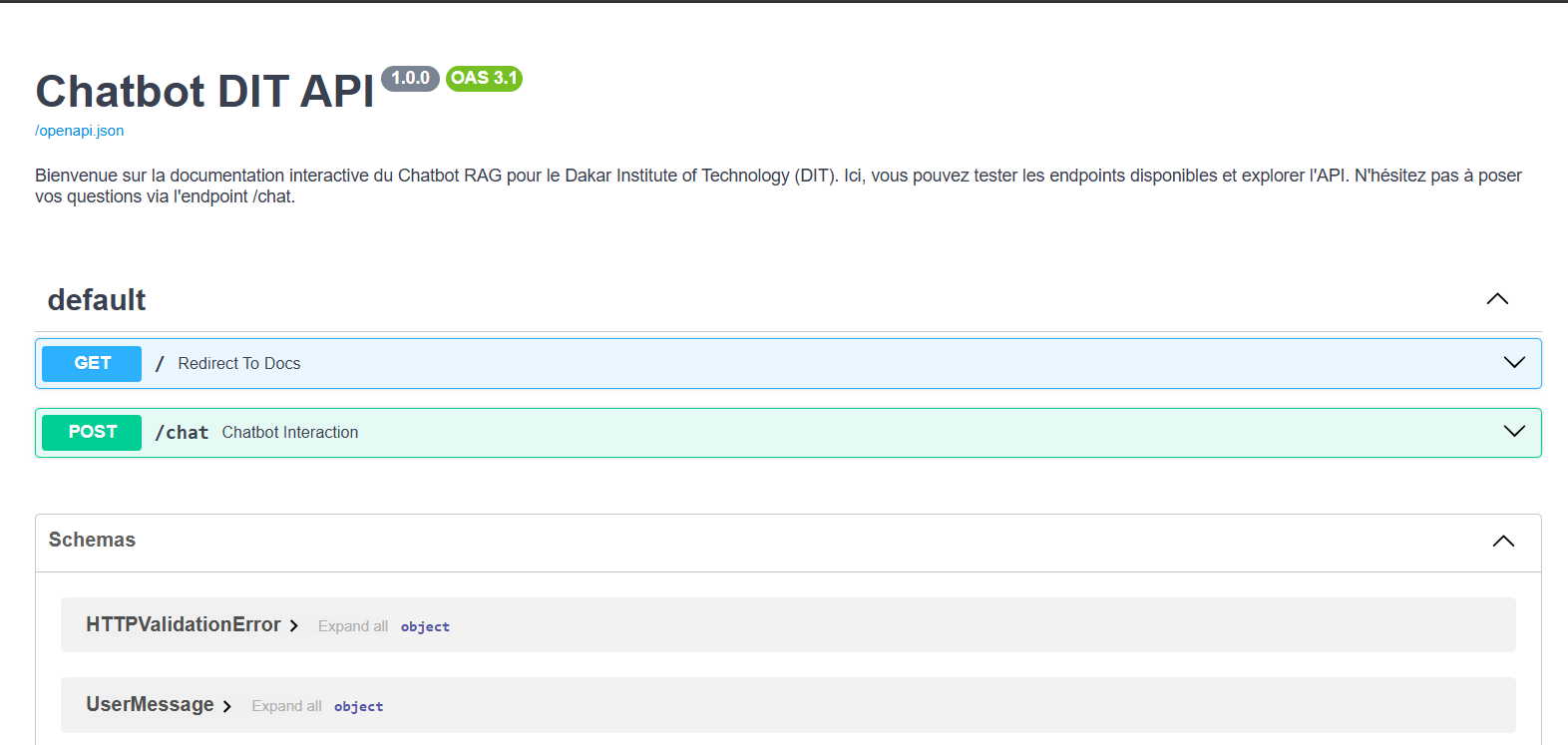 L’interface de documentation interactive générée automatiquement par FastAPI
L’interface de documentation interactive générée automatiquement par FastAPI

Schéma de l’architecture : Retrieval → Augmentation → Generation
Ce que Nico M’a Appris
Nico n’est pas un oracle. Il ne comprend pas vraiment les questions qu’on lui pose. Il ne “pense” pas.
Mais il fait quelque chose de remarquable : il récupère l’information pertinente et la restitue de manière fluide, naturelle, presque humaine.
C’est la force du RAG — combiner la précision de la recherche documentaire avec la fluidité de la génération de texte.
Leçons Techniques
- Les LLM seuls ne suffisent pas pour des cas d’usage factuels. Il faut leur donner un contexte.
- La qualité des réponses dépend avant tout de la qualité des données. Un modèle brillant sur des données médiocres donnera des réponses médiocres.
- Un bon prompt vaut mieux qu’un modèle plus puissant mal guidé. L’ingénierie du prompt est un art en soi.
- La simplicité architecturale est souvent la meilleure approche. Pas besoin de sur-ingénierie pour résoudre un problème réel.
Leçons Humaines
- Un chatbot ne remplace pas l’humain. Il le libère des tâches répétitives pour qu’il puisse se concentrer sur ce qui compte vraiment — penser, créer, transmettre.
- La technologie n’a de sens que si elle sert un besoin réel. Construire pour construire ne sert à rien.
- Partager ses connaissances multiplie leur valeur. Un projet qui reste dans un tiroir (ou sur GitHub sans documentation) est un projet perdu.
Si vous souhaitez explorer le code en détail, reproduire ce projet, ou l’adapter à votre contexte, tout est disponible sur GitHub : Chatbot RAG - Nico
N’hésitez pas à l’adapter, à l’améliorer, à le critiquer. C’est comme ça qu’on progresse — ensemble.
Pour aller plus loin
Ressources sur le RAG :
Outils et frameworks :
- FastAPI Documentation
- Google Gemini API
- Alternative Vector Stores : Chroma, Pinecone, Weaviate
Lectures recommandées :
- Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks (Lewis et al., 2020)
- The Illustrated Transformer
- Prompt Engineering Guide
Dans ce voyage entre recherche et génération, nous avons vu qu’un assistant intelligent n’est pas celui qui sait tout, mais celui qui sait où chercher.
Nico ne pense pas. Mais il restitue fidèlement. Et parfois, c’est exactement ce dont nous avons besoin.
Un gardien des savoirs qui ne dort jamais, qui ne se trompe pas volontairement, qui reste humble dans son ignorance.
Magiquement vôtre,
M. Royce